Creating & Configuring an ETL¶
This section will walk-through the creation of an ETL. Launching a new ETL requires the following steps:
- Prepare the end-point (e.g., Socrata) with the columns and data set name.
- Configure the ETL parameters (e.g., 4x4 ID) and control file.
- Write an ETL
Initial preparation¶
First, the end-point must be configured. With a Socrata portal, create all of the columns with API field names. If you have an initial extract, a recommended workflow is to upload it to the dataset. Otherwise, the columns can be created manually by the user.
Find the Socrata 4x4 of the newly created dataset.
Create a new folder with the dataset name and 4x4 in the ETL
directory (i.e.,
open-data-etl-utility-kit/ETL/Data_Set_Name_abcd-1234).
Write ETL¶
A basic template of a new ETL is at
open-data-etl-utility-kit/ETL_Template.ktr. Copy it to the new
directory with a name maching the directory, such as:
$ cp ETL_Template.ktr ETL/Data_Set_Name_abcd-1234/Data_Set_Name_abcd-1234.ktr
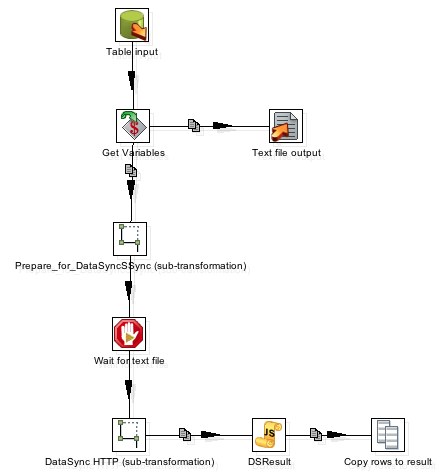
Open the file in Kettle. Several steps are included, but the following items should not be modified:
- Get Variables
- Prepare_for_DataSyncSSync (sub-transformation)
- Wait for text file
- DataSync HTTP (sub-transformation)
- DSResult
- Copy rows to result
- Text file output
Users should modify the data extraction (such as Read Table or JSON Input) and any custom transformation.
Configuring ETL parameters¶
In Kettle, select Edit -> Settings..., then click on the
“Parameters” tab. Fill-in the appropriate fields for each parameter,
typically along the following lines:
- P_ControlFile - Name of control file (e.g., Data_Set_Name_control.json)
- P_DatasetID - Dataset 4x4 (e.g., abcd-1234)
- P_File - File name of the file DataSync should use for the update (e.g., Data_Set_Name_abcd-1234.csv)
Move the DataSync configuration template file (_control.json) to the new directory, renaming it in the process:
$ cp _config.json ETL/Data_Set_Name_abcd-1234/Data_Set_Name_control.json
Edit the configuration file by inserting the appropriate API field names.
Suggested naming conventions¶
It can be difficult to manage dozens, if not hundreds, of ETLs. The
City of Chicago data science team names each folder and Kettle
transformation file with the same naming schema:
Name_of_file_abcd-1234, where abcd-1234 is the unique
four-by-four of the dataset. For instance, the city’s crime data
is saved under the folder Crimes_2001_to_present-ijzp-q8t2.